
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- #abc 프로젝트 멘토링 #유클리드소프트 #고용노동부 #대한상공회의소 #미래내일일경험사업 #공부일지 #멘토링일지
- #abc부트캠프 #유클리드소프트 #고용노동부 #대한상공회의소 #미래내일일경험사업
- Today
- Total
나른한 코딩 생활
[26일차] ABC 부트캠프 딥러닝의 기초 본문
26, 27일차는 엔비디아 엔버서더로 활동하고 계신 Young-Mook Kang ( 강영묵 ) 강사님께서
딥러닝의 기초를 강의해주실 예정이다
기술을 배우는 것 보다는 -> 즉, AI 모델들을 개발하는게 아닌, AI 모델을 이용하여 다른 프로젝트등에 접목하는 것이 중요하다
물론 아직까지는 AI 개발이 현재 불필요하다는 것은 아니다. 허나 이는 날이 갈수록 수요가 적어짖고 전문성이 떨어질 것.
사전 트레이닝된 모델 : 목적에 따라 훈련된 모델별 차이점이 나온다.
-> 이 모델들이 뭐가 있고 어느 때 쓸 수 있는지만 알면 실전에서는 충분하다
딥러닝 모델을 처음부터 끝까지 제작하는 회사는 매우 드물다.
개발? 이제는 찾는다는 표현을 사용하고 있다
내가 이룰 목적을 달성 가능한 모델을 찾는 것
컴퓨팅 능력과 데이터 양이 증가함에 따라 딥러닝이 발달하게 됐다
모델이 크면 클수록 ( 데이터 양이 많으면 많을수록 ) 딥러닝의 수준이 올라간다
TensorFlow , PyTorch, mxnet
Mnist 실습 복습
Dense : fully conected 된 레이어 / 앞이나 뒤 과정 간 상호연결되어 있임
units 개수나 활성화 함수등을 바꿔가면서 해보는것이(훈련시키는것) 좋다
model.add(Dense(units = 512, activation='relu'))
Dense -> 숨겨진 레이어를 하나만 실행했을 때의 출력문은 다음과 같다

모델의 크기를 아래 코드와 같이 키워봤다
model.add(Dense(units = 512, activation='relu'))
model.add(Dense(units = 1024, activation='relu'))
model.add(Dense(units = 2048, activation='relu'))
model.add(Dense(units = 512, activation='relu'))
model.add(Dense(units = 256, activation='relu'))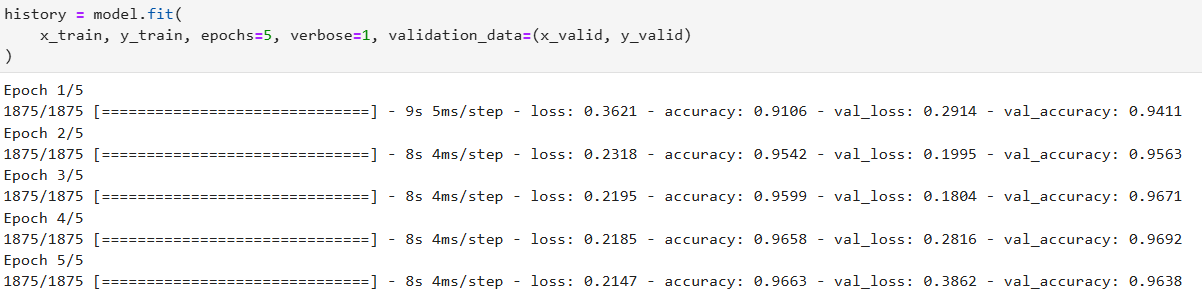
위에서 볼 수 있듯이 오히려 정확도는 떨어졌다 -> 모델이 클수록 좋다면서?!
모델을 키우기 위해서는 그만큼 데이터양도 받춰줘야하고
더많은 학습을 하고 더 많은 데이터를 줄 수 있으면 위에서 언급한 대로 모델은 클수록 정확도가 올라간다
Epoch 값에 따라 도달할 수 있는 값도 다양하다
CNN
Strides 값이 커질 수록 -> 이미지가 작아진다
Padding : 이미지를 확장시켜서 균등성을 부여
Kernel : 조와 조원들의 개념과 비슷하다
-> 조원들의 대표인 조장의 값만 해당 조의 의견으로 판단(값)
Max Pooling -> 해당 조 내에서 최대값만읗 취해서 커널시킴
Dropout : 일부러 뉴런 중 소수를 학습에 참여시키지 않고 학습률을 집중시키는 과정

그림이 더 크거나 고해상도일 경우에 더 복잡하거나 긴 모델이 나온다.
-> 물론 여기서도 적정 수준의 모델을 찾아야함
Dense / Conv2D 차이점?
Dense - 데이터를 처음부터 끝까지 분석해서 준다 --> 불필요한 데이터까지 (특징이외의 필요없는 데이터) 넘겨줌으로 학습에 어려움이 있을 수 있음
Conv2D - 특정 Feature에 대한
개 학습
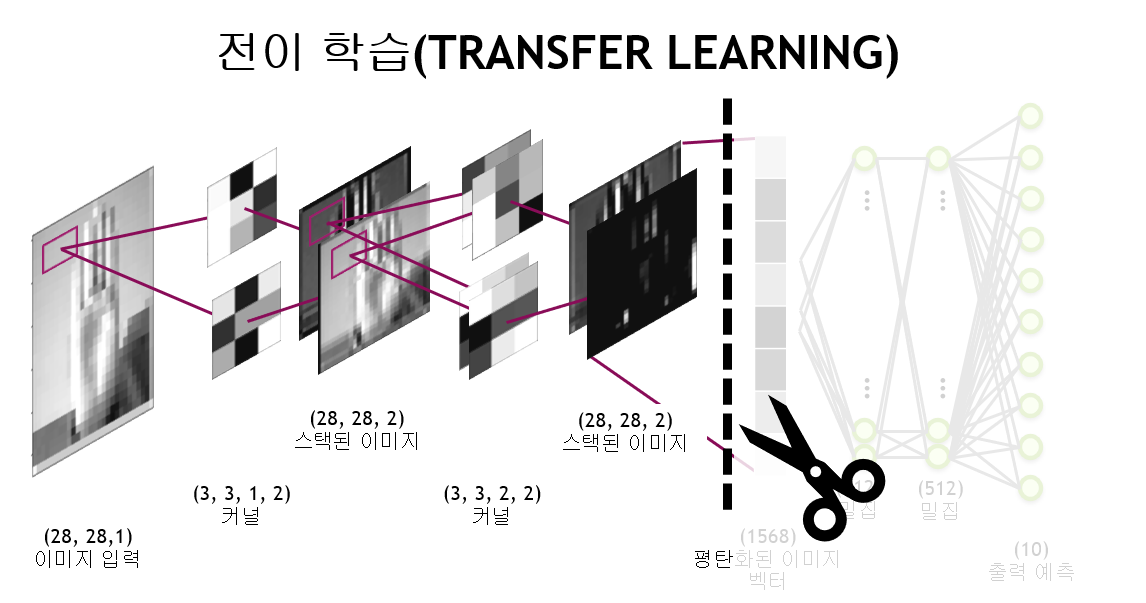
include_top = False
자른 부분 뒤에 부터는 내가 새롭게 분류한 개체에 학습에 사용하겠다
동결
binary crossentropy : True or False 와 같은 2개의 선택지 일경우
3개 이상의 멀티 일경우 accuricy? 엑큐리시로 사용
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# create a data generator
datagen = ImageDataGenerator(
samplewise_center=True, # set each sample mean to 0
rotation_range=10, # randomly rotate images in the range (degrees, 0 to 180)
zoom_range = 0.1, # Randomly zoom image
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=True, # randomly flip images
vertical_flip=False) # we don't expect Bo to be upside-down so we will not flip vertically
horizontal_flip = True 수평반전은 허용 하지만, vertical_flip = False 수직반전은 허용하지 않겠다
수료를 위한 프로젝트
ImageNet 기본 모델 로드
from tensorflow import keras
base_model = keras.applications.VGG16(
weights='imagenet',
input_shape=(224, 224, 3),
include_top=False)기본 모델 동결
# Freeze base model
base_model.trainable = False모델에 레이어 추가
# Create inputs with correct shape
inputs = keras.Input(shape=(224, 224, 3))
x = base_model(inputs, training=False)
# Add pooling layer or flatten layer
x = keras.layers.GlobalAveragePooling2D()(x)
# Add final dense layer
outputs = keras.layers.Dense(6, activation = 'softmax')(x)
# Combine inputs and outputs to create model
model = keras.Model(inputs, outputs)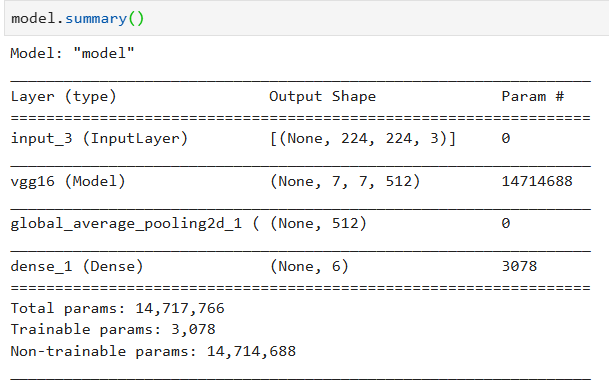
모델 컴파일
model.compile(loss=keras.losses.CategoricalCrossentropy(), metrics=[keras.metrics.CategoricalAccuracy()])CategoricalAccuracy
Accuracy 가 만능은 아닐 수 있다
ex)
암환자가 존재할때 -> 암환자가 아닌데 암환자로 처분 == 암환자인데 암환자가 아니라고 처분 ?
Accuracy : 해당 실수는 동일한 실수 1번으로 취급
하지만 이것은 전자와 후자의 가중치가 다르다
-> 결과에 따른 중요도(가중치)가 다를 경우에 Accuracy 보다는 다른 metrics를 (분류모델) 사용할 수 있다
데이터 증강
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=180, # randomly rotate images in the range (degrees, 0 to 180)
zoom_range=0.1, # Randomly zoom image
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=True, # randomly flip images horizontally
vertical_flip=True, # Don't randomly flip images vertically
)데이터세트 로드
# load and iterate training dataset
train_it = datagen.flow_from_directory('data/fruits/train/',
target_size=(224,224),
color_mode='rgb',
class_mode="categorical")
# load and iterate validation dataset
valid_it = datagen.flow_from_directory('data/fruits/valid/',
target_size=(224,224),
color_mode='rgb',
class_mode="categorical")모델 트레이닝
model.fit(train_it,
validation_data=valid_it,
steps_per_epoch=train_it.samples/train_it.batch_size,
validation_steps=valid_it.samples/valid_it.batch_size,
epochs=20)

파인 튜닝을 위한 모델 동결 해제
learning rate 는 저번에 설명했던 비선형 이차 함수의 그래프를 생각하면 좋을 것이다.

# Unfreeze the base model
base_model.trainable = True
# Compile the model with a low learning rate
model.compile(optimizer=keras.optimizers.RMSprop(learning_rate = 0.00001),
loss=keras.losses.CategoricalCrossentropy(), metrics=[keras.metrics.CategoricalAccuracy()])
다만 이것을 너무 무리해서 사용하면, 오히려 잘 분류된 데이터를 망가뜨릴 수 있다
-> 많은 데이터가 아닌, 적은 양의 epoch 혹은 학습량이라 accuracy 가 낮을 경우 사용한다고 볼 수 있다.
-> 이렇게 하더라도 힘들면 사전 모델을 바꾸는것도 좋다 ( 다른 인식모델 찾기 )
'ABC 부트캠프' 카테고리의 다른 글
| [28일차] ABC 부트캠프 데이터 라벨링 (0) | 2024.08.02 |
|---|---|
| [27일차] ABC 부트캠프 트랜스포머 기반 자연어 처리 애플리케이션 구축 (0) | 2024.08.02 |
| [25일차] ABC 부트캠프 정규화 / YOLO / 얼굴 학습 (0) | 2024.07.28 |
| [24일차] ABC 부트캠프 이미지 필터링 및 학습 (0) | 2024.07.28 |
| [23일차] ABC 부트캠프 패션 데이터 및 CNN (0) | 2024.07.27 |


